
Detailed analysis of Themida's LION VM (Part 2)
Intro
This is the second part of Themida’s Lion virtual machine analysis. If you haven’t yet read the first part, it’s highly recommended to do so to get an idea of virtual machine’s architecture and instruction set.
Disclaimer
This research is published for educational and defensive purposes to document the technology that malware, cheats, and other ill-intended software hide behind, so that anti-cheats, EDRs, and analysts can better understand it. It is not a slight against Oreans, whose engineers clearly built something impressive. Don’t use any of this to infringe anyone’s intellectual property.
Flow discovery
Lion VM is among Themida’s virtual machines that implement rolling decryption, meaning the keys used to decrypt offsets, opcodes, and other data change with the execution flow and are reset at the start. Therefore, to devirtualize an obfuscated program, instruction analysis must progressively follow the original program’s control flow.
Branch restoring
Real-world programs are rarely (if ever) linear, and the same applies to VM-obfuscated segments. To fully devirtualize a program, it’s necessary to explore all possible execution paths.
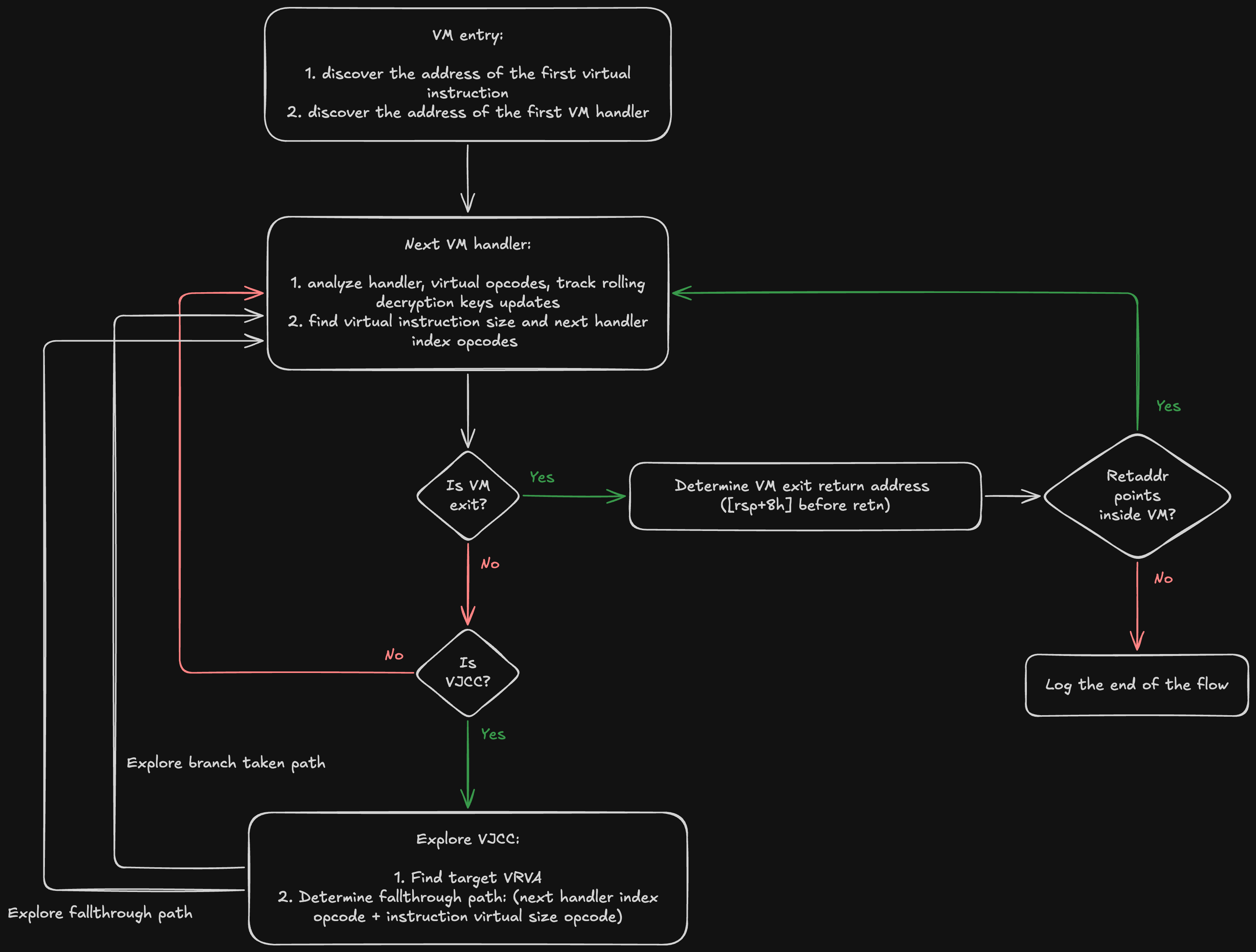
In all Themida virtual machines, there are three types of virtual instructions that affect control flow:
- VM exit - can be part of broader vmcall implementation, or an unconditional context switch and return to the host. In both cases, control flow is not branched, and VM exit virtual instructions can be parsed linearly
- VJMP - an unconditional jump to a virtual instruction, typically used to implement loops. When parsing virtual instructions sequentially, encountering a VJMP means the parser should unconditionally move to the jump’s target virtual instruction and continue discovery from there
- VJCC - a conditional jump to a virtual instruction. Just like conditional jumps in x86 (amd64), it splits the program into two separate paths that must be explored independently and later merged. The two paths to explore are the jump target and the fallthrough, in Themida the fall-through is computed as
vm_ctx->vip += vinstr_decoded->virtual_length
As established in the first part of Lion VM analysis, both VJCC and VJMP are easily located and intercepted. During progressive discovery, every time the discovery algorithm encounters a VJCC, both paths must be explored regardless of the runtime flag value.
Below is an example of the progressive virtual instruction discovery flow:
VM Behavior
Entering the VM
Lion VM has a clear entry pattern that goes beyond vm_entry_setup that preserves RFlags, pushes the virtual instruction offset, VM handler index, and return address (all decrypted from constants) onto the stack, and vm_entry itself that synchronizes the VM and initializes the VM context.
The very first virtual instruction is always VINIT: it updates multiple virtual registers (most of which are reset later regardless, making this section largely junk code) and resets several virtual register values to 0.
VINIT is then followed by the VSETUP virtual instruction, described in the first part. Here, the rolling decryption keys are reset to their constant values. In addition to the rolling decryption keys, the virtual control flow integrity byte is reset to 0, and the operation type field (used by merged handlers) is reset to a constant value.
After all temporary registers are reset, VSYNC_STACK_POINTER is executed. It stores the current RSP value in the VM context, effectively defining the VSP (virtual stack pointer). As described in the first part, the virtual stack reuses the host’s (amd64) stack space, and the VSP always equals the RSP value at VM entry minus 152 bytes, the total size of the data pushed onto the stack during vm_entry and vm_entry_setup.
After these three instructions, the host register values pushed onto the stack during vm_entry are stored in the VM context structure as virtual registers. The values are pulled from the stack using the VPOPQWORD instruction (sometimes via the VPUSH_POP merged handler). After every VPOP, the VSP value is increased by the size of the value popped from the stack (8 bytes), effectively maintaining the sync with the host’s RSP.
Ultimately, the guest prologue of virtualized region always looks like this:
vinit
vsetup
vsync_stack_pointer {vsp_offset}
vpop {host_rcx_offset}
vpop {host_rdx_offset}
vpop {host_rbx_offset}
vpop {host_rsi_offset}
vpop {host_rdi_offset}
vpop {host_r15_offset}
vpop {host_r14_offset}
vpop {host_r13_offset}
vpop {host_r12_offset}
vpop {host_r11_offset}
vpop {host_r10_offset}
vpop {host_r9_offset}
vpop {host_r8_offset}
vpop {virtual_flags_offset}
Leaving the VM
A VM code segment always concludes with a vm_exit instruction, which switches context and returns execution to the host, whether that is a parent VM in the case of nested VMs, or the amd64 host itself. vm_exit doesn’t do much on its own: it resets the spinlock acquired in vm_entry, restores host register values from the virtual stack, and returns to the host.
Before VM exit, all host register values are pushed onto the stack from their corresponding virtual registers using the VPUSH instruction (sometimes, via merged VPUSH_POP handler). Similarly to VPOP, the VSP is adjusted by +8 bytes every time a push is made.
When vm_exit is part of a broader vmcall instruction, the return address of the call is placed on top of the stack. This return address points to a vm_entry_setup stub, and each such stub is unique to its corresponding vmcall call site. However, all these stubs within the same virtual machine lead to the same vm_entry. As a result, vm_exit is the only virtual instruction other than VJMP that doesn’t have virtual instruction size and the next VM handler index opcodes encoded in its virtual instruction.
Compression
Themida VMs can optionally be compressed to reduce final file size. After compilation, the VM internals are compressed with LZMA and the compressed payload is placed in Themida’s section (Themida does not compress virtual machines generated in code caves, “Stealth” mode). Rather than using dynamic allocation to uncompress the VM to at runtime, Themida sets the virtual size of its PE section (section.Misc.VirtualSize) to the size of the uncompressed payload, so that the OS loader could allocate enough memory for decompression while the file itself remains smaller.
A compressed VM has a different entry point (a bridge) from an uncompressed one. The difference begins at the point where control flow is transferred from the original unobfuscated code to the VM-obfuscated segment, uncompressed entries use a simple jmp {rva} instruction pointing directly to vm_entry_setup, while compressed entries use a call {rva} followed by push rax (pattern E8 ?? ?? ?? ?? 50).
The compressed VM bridge begins by preserving flags via pushfq, followed by a call with a zero RVA, to calculate mapped image base and Themida section base without relying on relocations later. It then stores the resolved image base in the c_vm_data structure, which is located at the very start of Themida’s section in the binary. The structure definition is below:
struct c_vm_bridge;
struct c_vm_data {
uint32_t m_compressed; // 0x0, whether the VM is compressed and needs to be decompressed, can be 1 or 0, essentially a BOOL check
uint8_t reserved_0004[0x4]; // 0x4, reserved bytes, unused
uint64_t m_image_base; // 0x8, mapped image base (in memory)
uint32_t m_compressed_size; // 0x10, the size of LZMA-compressed payload (predefined)
uint8_t reserved_0014[0x4]; // 0x14, reserved bytes, unused
uint64_t m_uncompressed_payload; // 0x18, mapped address of uncompressed payload
uint64_t m_compressed_payload; // 0x20, mapped address of LZMA-compressed payload
uint32_t m_vm_section_start; // 0x28, RVA of the Themida's section (predefined)
uint8_t reserved_002C[0x4]; // 0x2C, reserved bytes, unused
uint32_t m_compressed_payload_rva; // 0x30, RVA of LZMA-compressed payload to Themida section start
uint8_t reserved_0034[0x4]; // 0x34, reserved bytes, unused
uint32_t m_reloc_count; // 0x38, relocation count in the VM (manual fixup)
uint8_t reserved_003C[0x4]; // 0x3C, reserved bytes, unused
uint64_t m_og_image_base; // 0x40, original image base, same as NtHeaders->OptionalHeader.ImageBase (predefined)
c_vm_bridge m_vm_bridges[1]; // 0x48, pairs of RVA of call -> RVA of corresponding VM entry (predefined)
};
struct c_vm_bridge {
uint32_t m_call_rva; // 0x0, RVA of the call from the original code to the VM (predefined)
uint32_t m_vm_entry_rva; // 0x4, RVA to VM entry to jump to after decompression (predefined)
};
There is only one decompression bridge per binary, and all compressed VM references point to it. After decompression completes, the bridge determines which vm_entry to redirect execution to by searching the m_vm_bridges array for a matching call RVA. It iterates the array until it either finds a matching entry or encounters a terminating <0, 0> pair, then jumps to the corresponding vm_entry.
Bytecode decryption
Lion VM encrypts most of its virtual instruction opcodes. With rare exceptions (such as VJCC, VJMP, VRDTSC, and some others), VM handlers decrypt virtual opcodes using rolling decryption keys and immediate values via the following arithmetic and bitwise operations: ADD (+), SUB (−), XOR (^), AND (&), and OR (|). As a result, the virtual registers serving as rolling decryption keys must be predictable and must reset with the virtual machine state.
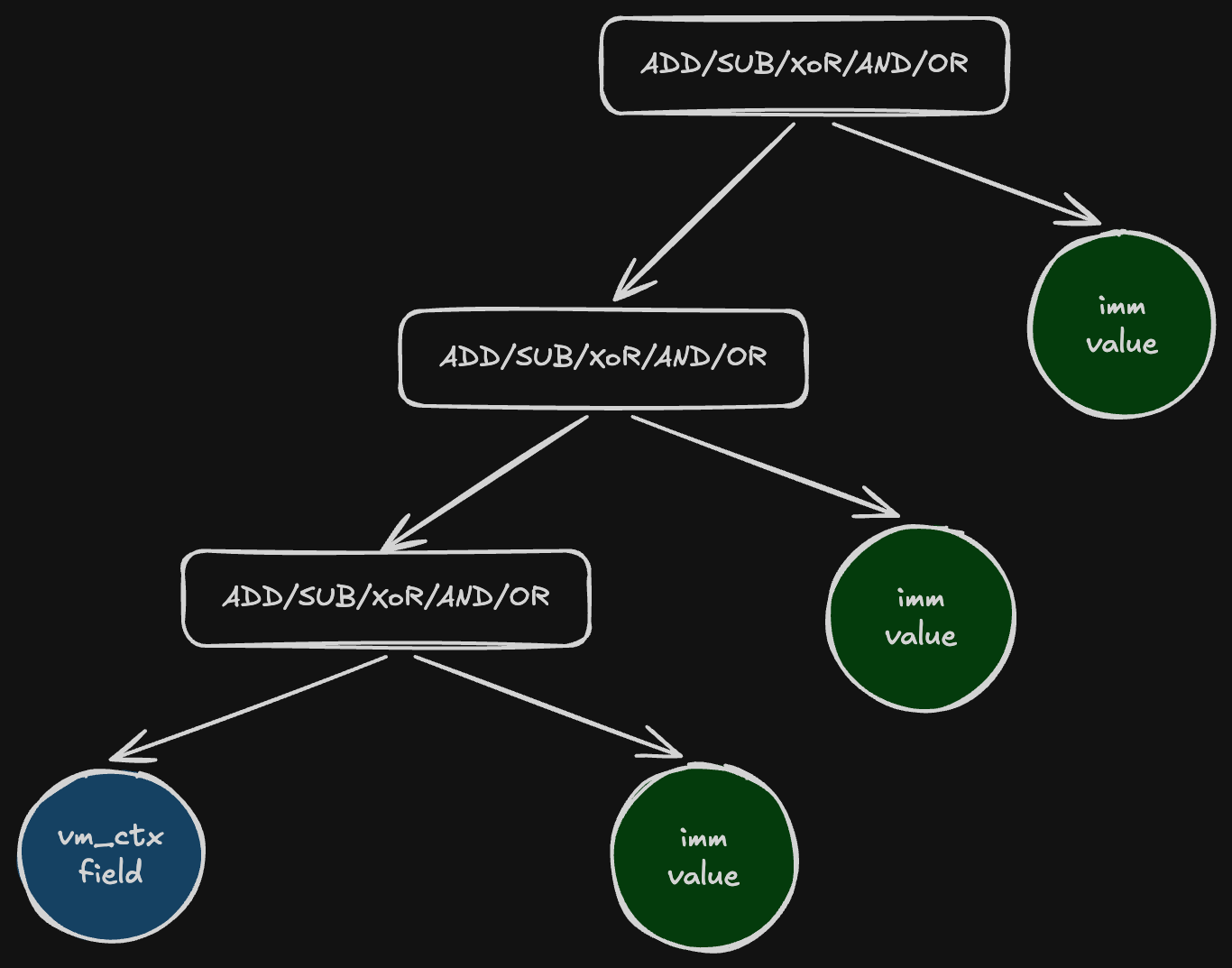
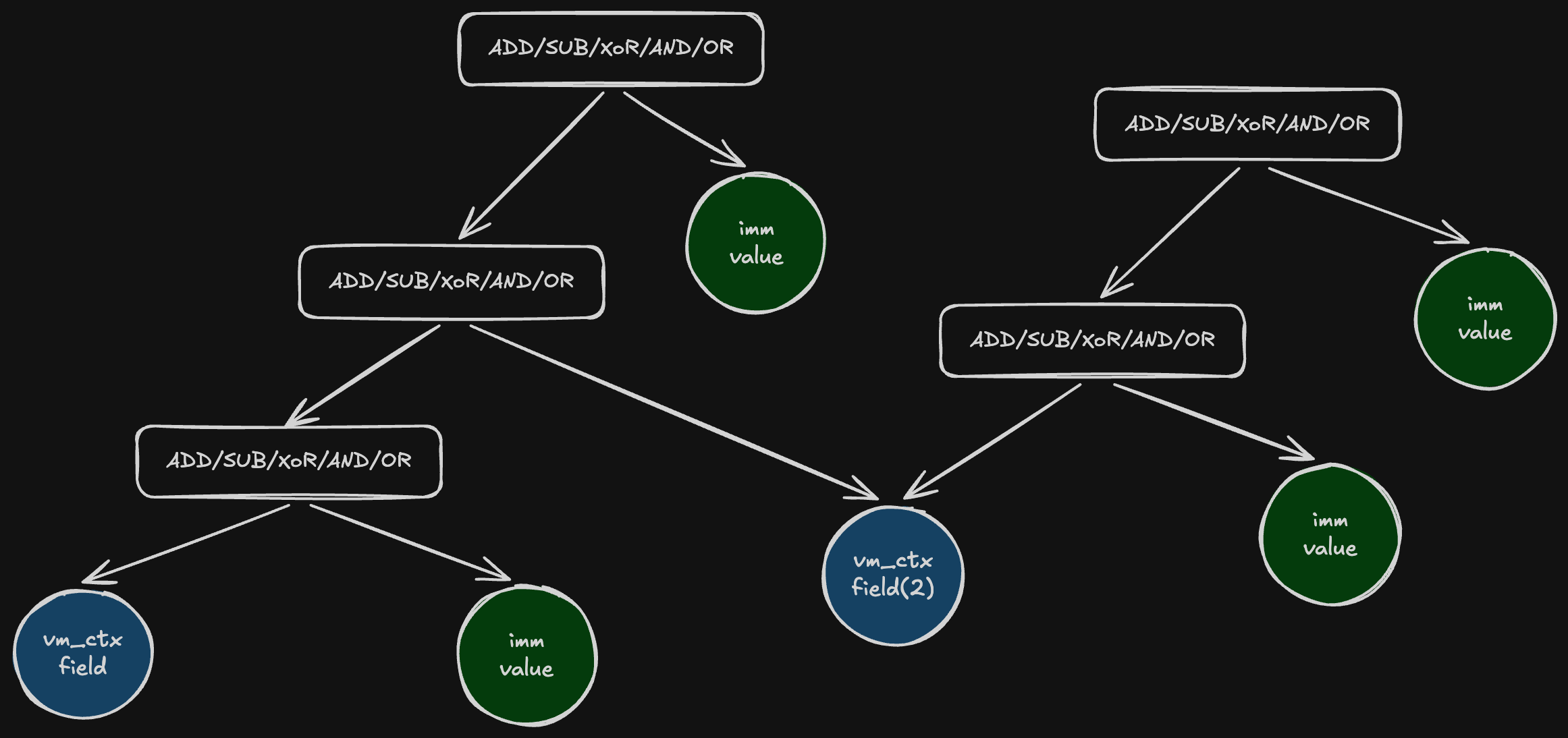
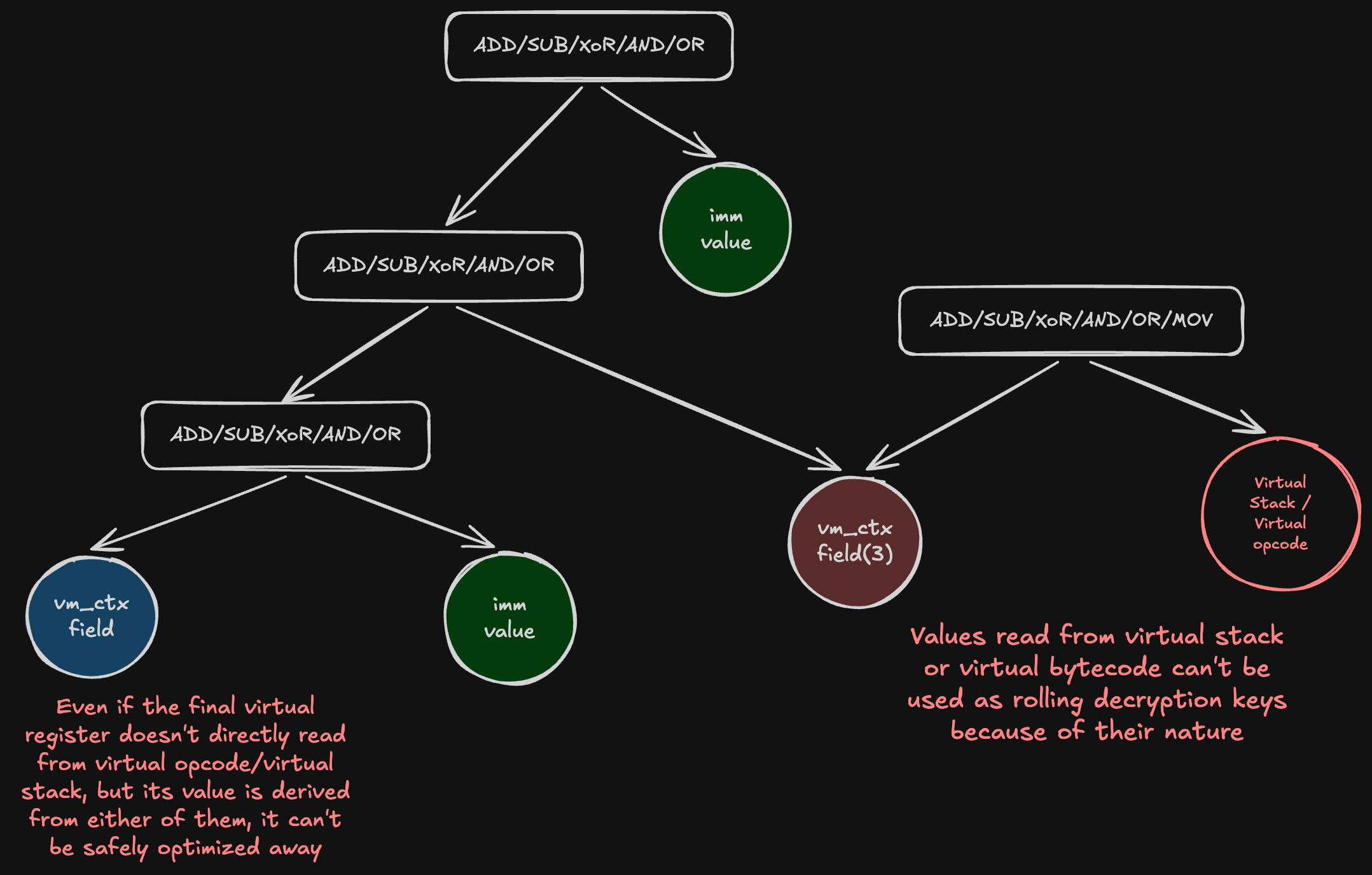
To identify a rolling decryption key, it is sufficient to analyze its AST at the point of use. The AST of a rolling decryption key must contain only immediate values — rolling decryption keys cannot be derived from dynamic values. There is one exception: rolling keys may be exchanged with or updated based on one another; however, this doesn’t make rolling key identification impossible, as the recursive nature of the criterion handles this case explicitly in step 3 below.
Full decryption of a virtual opcode is possible with the following approach:
- Find all dereferences (memory operand reads) of virtual instruction pointer values. For example,
mov rax, qword ptr [rbp+{vip_offset}]->movzx rax, word ptr [rax+0x2]can be considered an opcode read. The same applies to dynamic VIP-based dereferences such asmov rax, qword ptr [rbp+{vip_offset}]->mov rdx, qword ptr [rbp+{rnd_offset}]->movzx rax, byte ptr [rax+edx*2]. - Analyze all execution paths of the handler and determine where each virtual opcode value is actually used, meaning where it affects CPU state or where it is used as a memory address. At the point of use, the opcode’s AST can be evaluated: any immediate values present in the AST that modify the virtual opcode’s value are always decryption constants.
- If dynamic VM context field values are present in a virtual opcode’s AST, each can be evaluated as a potential rolling decryption key as follows: build the AST of the VM context field from the point where it appears as a node in the virtual opcode’s AST, back to that field’s definition. If a clear reset (unconditional redefinition) of the given VM context field exists, it can be classified as a rolling decryption key provided it is updated exclusively with constants or with other VM context fields that themselves qualify as rolling decryption keys. When another VM context field’s node appears in the AST, it must be replaced with that field’s own AST, and this process must be repeated until all remaining fields have been traced back to their resets and only immediate values remain in the fully expanded AST. When such an AST can be constructed, the entire rolling decryption chain can be optimized away.
Rolling key’s AST derived from constant values only:
Rolling key’s AST derived from constant values combined with other rolling keys:
Non-rolling key virtual register’s AST:
CPU flags mapping
Instead of relying on the RFlags (EFLAGS) register, Lion VM maintains flag storage and updates via a dedicated virtual register in the VM context. For example, the behavior of a simple:
cmp eax, 0
jz $target
becomes:
; VALU handler
mov rax, qword ptr [rbp+{vreg_offset}]
cmp eax, 0
pushfq
pop qword ptr [rbp+{flags_vreg_offset}]
; VJCC handler
mov byte ptr [rbp+{branch_taken_offset}], 0
; ...
mov eax, dword ptr [rbp+{flags_vreg_offset}]
and eax, 0x40 ; check if ZF bit is set
jz .not_set
mov byte ptr [rbp+{branch_taken_offset}], 1
.not_set:
; ...
; ... conditionally dispatch to the next virtual instruction based on vm_ctx->branch_taken value
This can be mapped back to the native AMD64 flag model. To do so, every write to the virtual flags register should be logged. The write pattern maps cleanly to the original, unobfuscated program’s behavior. For example, across all VALU handler variants, the virtual flags register is always updated whenever an arithmetic operation is performed, mirroring how real x86 arithmetic instructions update RFlags.
Upon reaching a VJCC handler, the flag check type can be determined from the mask used: if the virtual flags value is checked against & 0x40, this corresponds to a JZ/JNE pair (ZF=1); if checked against & 0x41, this corresponds to a JA/JBE pair (CF=0, ZF=0) etc.
Each VJCC is semantically driven by the most recent VALU predecessor that updated the virtual flags register. As a result, all VALU virtual register operations can be mapped back to amd64 registers by tracing the following chain: the VJCC handler (condition type) -> the last VALU handler that updated the virtual flags register (identifies which virtual register the VALU operation itself was performed on) -> the VPOP handler that updated that virtual register (SP offset) -> match VPOP’s VSP offset against the SP formed at vm_entry to find which amd64 register was mapped to the virtual register.
Multiple VM instances
No behavioral and semantic differences were observed in programs compiled with more than one Lion VM instance. Additional instances appear to exist in the binary but are never executed. This is either a bug in Themida (Code Virtualizer), or the instance count setting is dormant and has no effect on the obfuscation ¯\_(ツ)_/¯.
Nested VM instances (under-VM context switches)
Although Lion VM doesn’t implement nested virtual machines in any of its variants (Lion Black, Lion Red, and Lion White), nested VMs do exist in other, more complex Themida virtual machines such ad EAGLE BLACK VM, which has multiple layers of virtualization.
Second layer and deeper virtual machines are not true child VMs of the parent VM. They operate independently on the amd64 state, just as the first layer VM does. This means that what gets saved and modified in the inner VM is not the parent VM’s virtual registers, but the original amd64 registers. After the inner VM exits, the AMD64 register values are written back into their respective virtual register slots in the parent VM.
Essentially, calling this approach “nested virtual machines” is incorrect, “context switch” is a more accurate term for this.
Final words
This is the end of Themida Lion VM analysis series, however, we’re not done with Themida and other popular commerical VM-style obfuscator(s) that are frequently used for malware and gamehacks obfuscation just yet. In the next blogpost, we’ll put my devirtualization engine to the test, particularly, we’ll attempt full devirtualization regardless of individual VM, its complexity, whether it has multiple nested instances and whatnot.
On another note, I’d like to share a bunch of very useful resources about software deobfuscation and simplification:
- Inspecting Virtual Machine Diversification Inside Virtualization Obfuscation
- Symbolic deobfuscation: from virtualized code back to the original
- Efficient Deobfuscation of Linear Mixed Boolean-Arithmetic Expressions
- VMProtect 2 - Detailed Analysis of the Virtual Machine Architecture
- Pushan: Trace-Free Deobfuscation of Virtualization-Obfuscated Binaries
- QSynth - A Program Synthesis based Approach for Binary Code Deobfuscation
- … and many more not less impressive researches, blogs and findings by a bunch of cool people
Tools used for research and development:
As for now, I have to say goodbye although not for long. Ciao :)